We are happy to share that CHORD has been accepted to ACM MM 2025. CHORD studies how to give each user a personalized recommendation model that runs on their own device, without training or fine-tuning a separate model per user.
On-device recommendation is attractive because it is private, low-latency, and reduces server load. Making the on-device model personal, however, is expensive: one either fine-tunes on the device, which requires backpropagation, or ships a fresh model to every user, which consumes substantial bandwidth. CHORD instead casts personalization as a quantization problem rather than a training problem.
The challenge: customization and compression at the same time
Device-cloud recommendation faces several tensions simultaneously:
- Interest and resource heterogeneity. Users differ in taste, and their devices differ in memory, compute, and bandwidth.
- Evolving interests. User behavior drifts over time, so a one-shot deployment becomes stale.
- Frequent transmission under limited bandwidth. Distributing updated weights to many devices is costly.
The result is a coupled requirement: a model must be customized to the user and compressed to the device simultaneously, while keeping device-cloud communication inexpensive.
CHORD in one idea: find the ideal channel-wise quantization strategy for each instance
CHORD is built on a single principle:
Frozen weights + a channel-wise quantization strategy = fast and personalized adaptation.
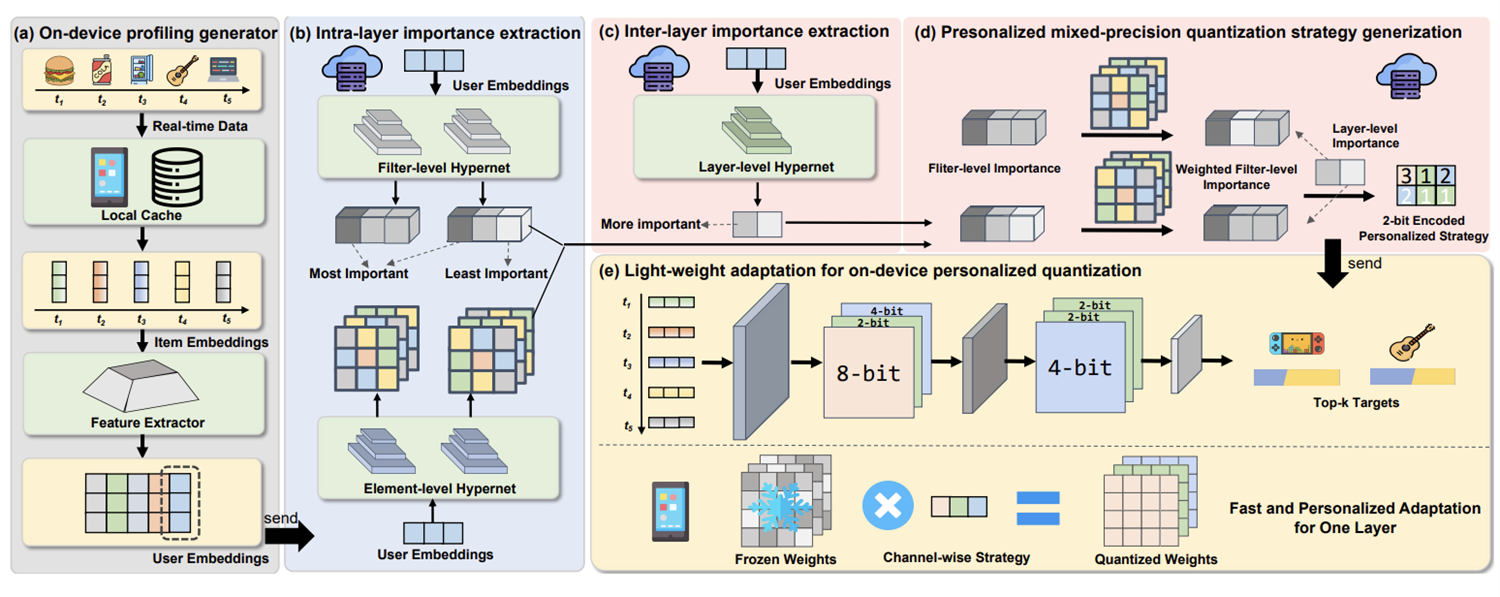
The central observation is that personalization can be expressed as a "lottery ticket" inside mixed-precision quantization. Every device keeps the same frozen backbone; personalization is encoded entirely as a per-user, per-channel bit-width assignment — which channels retain higher precision and which are quantized more aggressively. Searching for this winning bit-width pattern is performed off-device, while applying it on-device requires no training.
This yields three properties simultaneously: an importance-aware mixed-precision (~3-bit) model for efficient inference, a compact strategy of 2 bits per channel for transmission, and adaptation in a single forward pass, without on-device backpropagation.
Generating the personalized strategy
The strategy is produced by three components:
- User profiling generator. From the user's real-time interactions, the model derives latent interest embeddings that summarize the user's current interests.
- Multi-granularity sensitivity generator. A set of hypernetworks estimates parameter importance at three granularities — element, filter, and layer. Filter-level importance is reconstructed from element-level signals and then weighted by layer-level importance.
- Personalized strategy generator. The combined importance is converted into a channel-wise mixed-precision strategy: sensitive channels retain higher precision, the remainder are quantized lower. Only the strategy — not the weights — is encoded and transmitted, and it is decoded on-device according to the available resource budget.
Why it is efficient
The design pays off along four axes at the same time:
- Better recommendation — models are personalized to each user rather than shared across all users.
- Faster adaptation — a single forward pass, with no on-device training.
- Faster inference — an importance-aware mixed-precision (~3-bit) model.
- Lighter transmission — only 2 bits per channel are transmitted, instead of full 32-bit weights.
Experiments
We evaluate CHORD on three real-world datasets (Amazon-CDs, Yelp, ML-100K) with two standard sequential-recommendation backbones, SASRec and Caser, reporting NDCG@5/10 and HR@5/10. Against both full-precision and compressed baselines, CHORD achieves higher recommendation performance, higher inference and adaptation efficiency, and lower transmission overhead.
Beyond the main comparison, the paper further shows that CHORD:
- degrades gracefully under tighter budgets and supports different average bit-widths for adaptive deployment;
- supports weight–activation quantization, not only weight quantization;
- trains stably while reaching higher performance; and
- through visualization, confirms that importance is genuinely heterogeneous across both layers and channels — which is what makes a per-user, per-channel strategy worthwhile.
Takeaway
Personalizing an on-device model need not require training one per user. CHORD reframes customization as searching for a per-user quantization lottery ticket and splitting the work across device and cloud — shared frozen weights, a compact channel-wise strategy, and a single forward pass. This device-cloud, quantization-first formulation offers a practical path to personalized models that remain deployable on resource-constrained devices.
Further reading