We are happy to share that Graph2Eval has been accepted to CVPR 2026.
Agent benchmarks are moving fast, but many evaluations still rely on fixed datasets and leaderboard scores. That setup is easy to run, yet it creates a familiar risk: models may improve on a narrow test distribution through memorization or overfitting, while true tool use, information understanding, and multi-step reasoning remain under-tested.
Graph2Eval takes a different angle. Instead of asking an LLM to invent tasks from raw text alone, we first build a knowledge graph (KG) from external documents and web pages, then sample structured subgraphs and instantiate tasks from that graph. The goal is evaluation that stays scalable, controllable, and semantically grounded.
The problem with static agent benchmarks
Static datasets are invaluable as baselines, but they struggle to keep pace with agent capabilities and deployment settings:
- Limited scalability. Manual annotation and fixed environment design are expensive to extend.
- Weak semantic structure. LLM-only synthesis often misses explicit entity–relation modeling, which can hurt task consistency and solvability.
- Narrow transfer. Tasks built from simplified or frozen page layouts may not reflect dynamic real-world websites.
In other words, a high score on a fixed suite does not automatically mean an agent will generalize when the environment changes.
Graph2Eval in one pass
Graph2Eval treats the KG as a latent task space. The pipeline has five stages:
- Data ingestion — parse documents and crawl web pages while preserving layout semantics (headings, tables, links, forms, screenshots).
- KG construction — map entities and interactions to nodes and edges with multimodal representations.
- Subgraph sampling — extract task-relevant structures via templates and meta-path strategies.
- Task generation — compose executable task instances with LLM-assisted context engineering.
- Coverage optimization — filter tasks with reachability checks, LLM scoring, and similarity analysis.
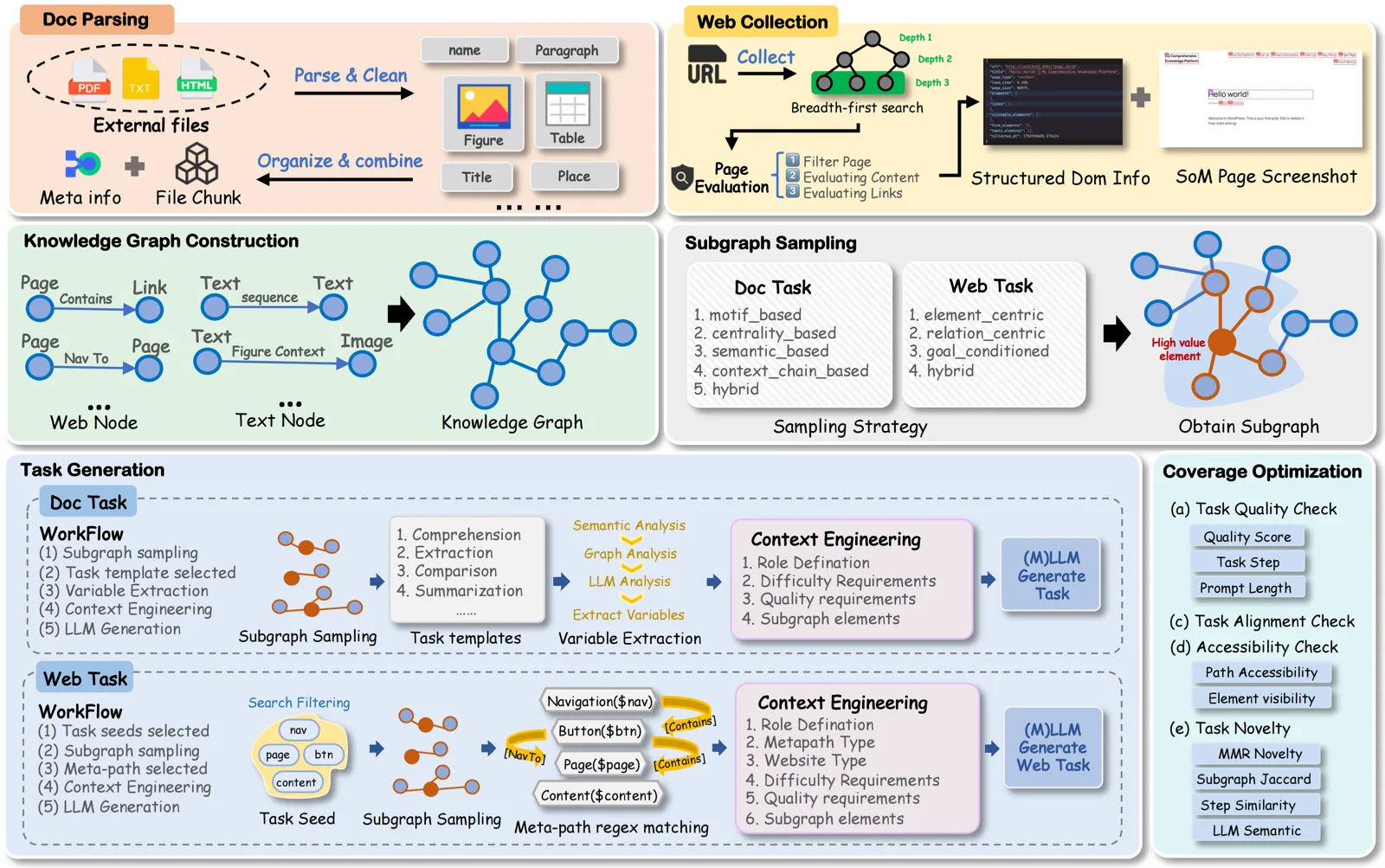
This design supports both RAG agent scenarios (multimodal document understanding) and web agent scenarios (multi-step interaction on realistic pages).
Why the knowledge graph matters
The KG is not just metadata decoration. It gives us a place to enforce structure before task text is written:
- Nodes capture paragraphs, headings, hyperlinks, forms, buttons, tables, and related UI elements.
- Edges encode semantic, structural, and interactive relations across content.
- Meta-paths specify which node types and relations a valid task should traverse.
Sampling a subgraph first makes it easier to control what the task is about before generating natural-language instructions. That reduces the “plausible but unsolvable” failure mode common in free-form LLM task synthesis.
What you can control
A major advantage of graph-based generation is explicit control over task difficulty and capability coverage:
| Knob | What it changes |
|---|
| Path length | Overall task complexity and number of reasoning hops |
| Node-type constraints | Which skills are required — retrieval, reasoning, UI operation, etc. |
| Sampling strategy | Task distribution and diversity across the benchmark |
This is the difference between a leaderboard that measures familiarity and an evaluation pipeline that measures adaptation under changing structure.
Graph2Eval-Bench and results
We instantiated the framework as Graph2Eval-Bench, a curated set of 1,319 tasks:
- 1,002 document-understanding tasks
- 317 web-interaction tasks
Compared with a KG-free baseline, Graph2Eval improves average semantic consistency by 20% and solvability by 17%. Generation is also practical: about 35 seconds per document task and 96 seconds per web task on average. Across LLM configurations, Graph2Eval-Bench provides clearer separation of agent performance than static suites alone.
Takeaway
We believe agent evaluation should move toward dynamic, structure-aware task generation — not just larger static test sets. Graph2Eval is our step in that direction: use graphs to define what a task means, then generate language and interaction around that structure.
If you are working on agent benchmarking, RAG systems, or web agents, we would love to hear your feedback.
Further reading